
Today, i will discuss about the component “Merge Rows(Diff)” in Pentaho. See the below transformation for the same.
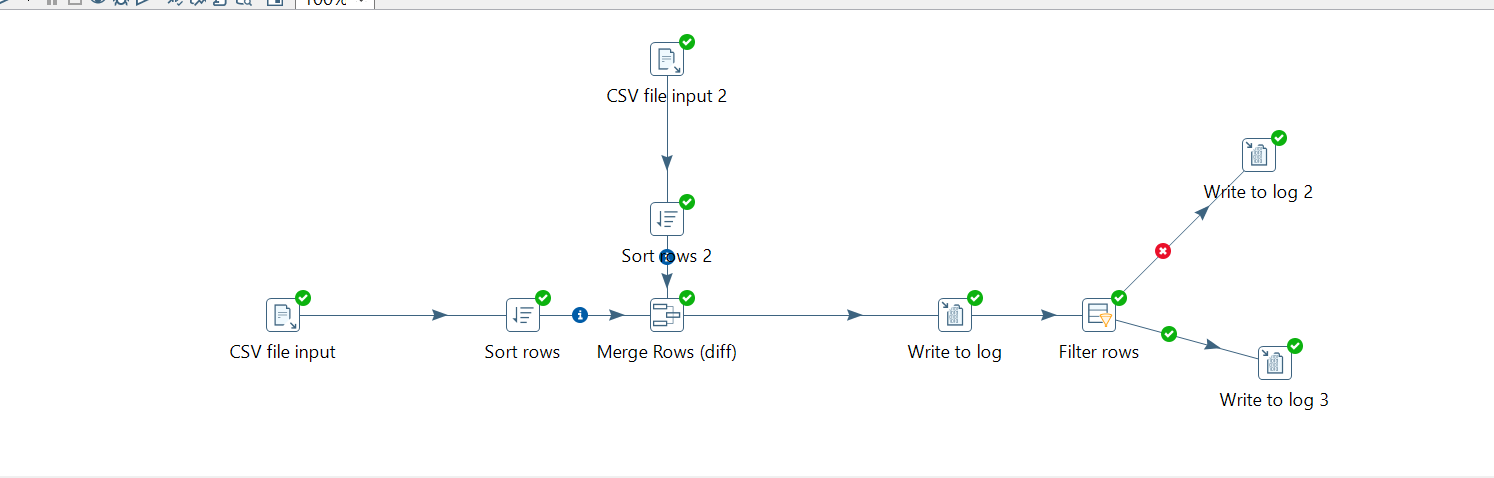
Before we start discussion on Merge Rows, always remember to sort the data on common columns from both streams before you add Merge row component. Otherwise results will not be correct.
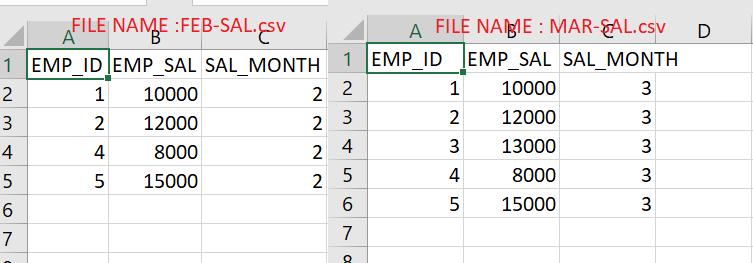
Here , i considered two CSV files which has data of employees. See the below images for the same.
Here MAR-SAL.csv is mapped to Reference rows origin field in Merge rows component and FEB-SAL.csv is mapped to Compare rows origin field in Merge rows component. See the below SS for the same.
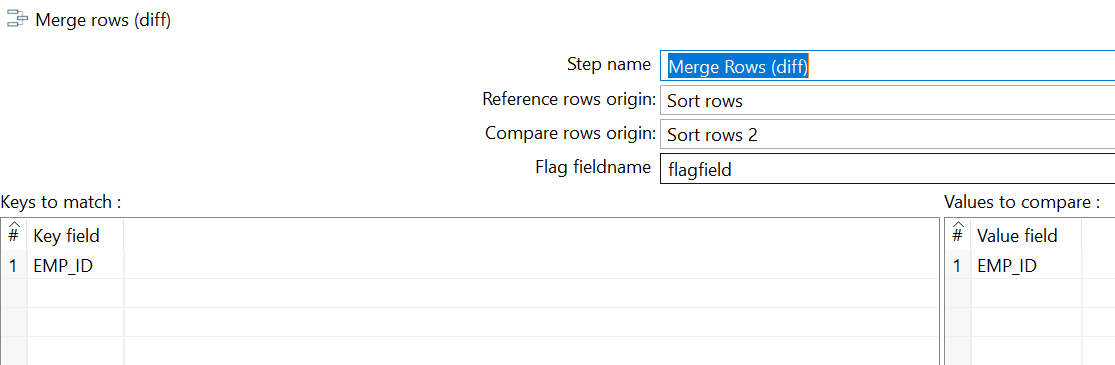
The files has fields EMP_ID,EMP_SAL,SAL_MONTH. Here, we will compare the emp_id from the both the files. Before that, we sort both the files on EMP_ID using sort rows component. Once sorting is done, we will merge the files using merge Rows component. It is very important that we should know why we are using this component. Here I am using this component in a way if rows will not match , i will perform function “A”. If rows matches , then i will perform function “B”. In Merge rows component, there are two fields “Reference rows origin” and “Compare rows origin“. When you compared the two streams of data, merge rows returns field named flagfield which has three values namely identical,deleted,new.
IDENTICAL : When rows matches based on compared columns , the flagfield marked as identical and data of “Compare rows origin” flows to the next job or transformation
DELETED: The rows which are present in “Reference rows origin” and not present in “Compare rows origin” are marked as deleted.
NEW: The rows which are present in “Compare rows origin” and not present in “Reference rows origin” are marked as “new”.
As you can see above, the MAR-SAL.csv has EMP_ID is 3 which is not present in FEB-SAL.csv, hence it is marked as deleted. See the below logs for the same.
Write to log 3.0 – EMP_ID = 3
Write to log 3.0 – EMP_SAL = 13000
Write to log 3.0 – SAL_MONTH = 3
Write to log 3.0 – flagfield = deleted
Assume, I add one more row in FEB-SAL.csv which looks like below
6,12000,2
Now,if you run the ETL transformation, you will see the flagfield for this row as new. See the below logs for the same.
Write to log 2.0 – EMP_ID = 6
Write to log 2.0 – EMP_SAL = 12000
Write to log 2.0 – SAL_MONTH = 2
Write to log 2.0 – flagfield = new
Hence, we can use the data which is matched and unmatched from both the files for further operations.